LENGUAJE DML.
La sentencia INSERT de SQL te permite insertar una fila en una tabla, es decir, añadir un registro de información dentro de una tabla. La sintaxis básica es:
INSERT [INTO] nombre_tabla [(nombre_columna, nombre_columna2, ...)]
VALUES ({expr | DEFAULT}, ...);
Donde nombre_tabla es el nombre de la tabla donde se quiere insertar la fila. Luego se pueden indicar las columnas a la que se quiera insertar valores. Por lo tanto es posible no seleccionar ninguna (en lo cual el valor introducido se aplicará a cada campo de la tabla si no está definido como NOT NULL), o establecer los campos en donde quedrás insertar contenido, con lo cual tendrás que crear un valor para cada campo de la tabla.
Así que partiendo de la anterior base creada Almacen, vamos a continuar insertando contenido dentro de las tablas asociadas. Escogeremos la tabla de clientes en donde insertaremos algunos clientes en la tabla. Para ello abre tu editor/consola y visualiza la estructura de la tabla. Eso lo haces con la instrucción describe nombre_tabla;, como vés en la imagen siguiente:
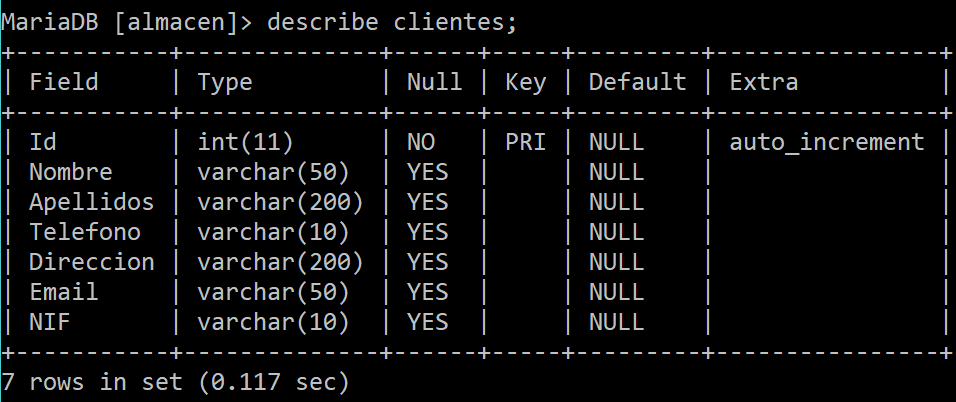
Como puedes ver el campo Id no es necesario que lo pongamos ya que tiene una característica de AUTO_INCREMENT, lo que hará que por cada registro insertado aumente su valor de manera automática. El resto de campos son alfanuméricos por lo que no habrá problemas. Vamos a insertar a un cliente en la tabla:
insert into clientes (Nombre, Apellidos, Telefono, Direccion, Email, NIF) values
('Pascual', 'Gomez del Pino', '555555555', 'Camino del rio Henares 1 4A 28128, Alcala', 'administrador@mirpas.com', '00000000A');
Con esto ya has insertado un registro en la tabla clientes. El problema es que esta forma de proceder solo puedes insertar un registro por cliente. Pero existe otra forma combinada de crear varios registros a la vez. Esto es separando las consultas por paréntesis como se ve a continuación que introduzco otros dos clientes más.
NOTA: Es posible que al crear la clave foránea en el anterior ejercicio, te impida introducir datos nuevos. Simplemente borrala y ya podrás otra vez introducir valores.

La sentencia SELECT.
Esta sentencia SQL es la más versátil de SQL. Es la que más uso se le da en cuanto a las operaciones de bases de datos, por lo tanto también es la más compleja, ya que se suele utilizar con una serie de filtros para personalizar la consulta.
La instrucción SELECT es una instrucción de consulta. Nos devolverá los registros de una tabla. Así en nuestra anterior tabla:
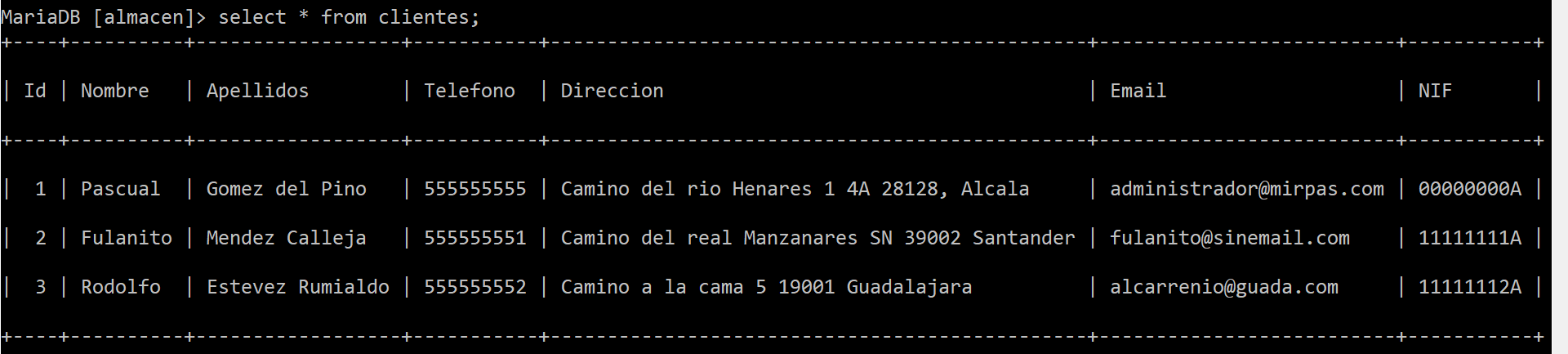
Observa como hemos cargado todos los registros de la tabla clientes al utilizar la sentencia SELECT y el comodín de ALL (*). Sino estableciesemos el comodín, deberíamos de establecer una columna específica o varias separadas con comas:
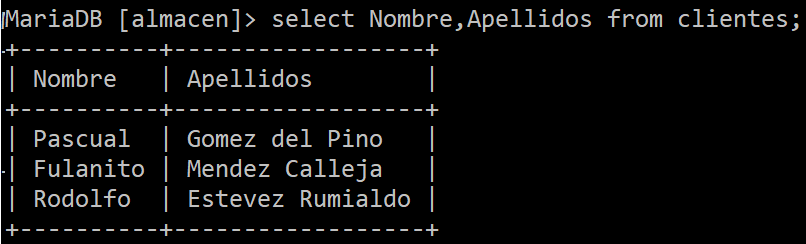
Basicamente desde SELECT podemos hacer consultas a las tablas de la base de datos y podemos personalizarlas de distintas manera con comodines y filtros específicos del lenguaje SQL. Sintácticamente SELECT funciona:
SELECT [DISTINCT] expresión_select, [expresión_selec]... [FROM tabla]
expresión_select:
nombre_columna [As alias] | * | expresión
nombre_columna, indica un nombre para la columna a consultar. como he mencionado se puede seleccionar una columna o varias columnas (o todas las columnas con el comodín *), pero también permite una expresión algebraica en las operaciones de SELECT.
Por ejemplo con el método concat() se pueden unir los valores de varios campos en un alias.

Además si utilizamos el comodín DISTINCT, solo nos mostrará registros que no estén duplicados. Asi que vamos a añadir un nuevo registro llamado Pascual con otro NIF y verás como al crear la consulta no aparece el campo Nombre repetido:

Fijate que en la tabla ahora existen 4 registros y dos de ellos se llaman 'Pascual'. Sin embargo la consulta DISTINCT solo muestra los que no están repetidos.
Filtros.
Los filtro son condiciones que cualquier gestor de bbdd interpreta para seleccionar registros de sus tablas y mostrarlos como resultados. En SQL la palabra más usada para crear filtros es la claúsula WHERE.
SELECT [DISTINCT] expresión_select [,expresión_select]... [FROM tabla]
[WHERE filtro]
Con este filtro podemos mostrar un registro específico (o varios), y un campo específico de dicho registro (o varios).

Existen una serie de expresiones para los filtros que permitirán ajustar la búsqueda en una consulta. Existen expresiones (tanto aritméticas como boleanas), que nos permitirán ajustar el filtrado en nuestras consultas. Por ejemplo en una tabla temporal podríamos hacer operaciones básicas de la forma:
SELECT (3+3)*9
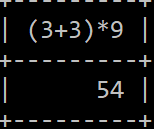
Fijate que aunque hemos creado una consulta temporal, podríamos aplicarla a cualquier campo de una tabla existente que tuviese su campo consultado a tipo de dato numerico. Y no solo podemos aplicar operaciones. También podemos aplicar funciones básicas del sistema SQL:
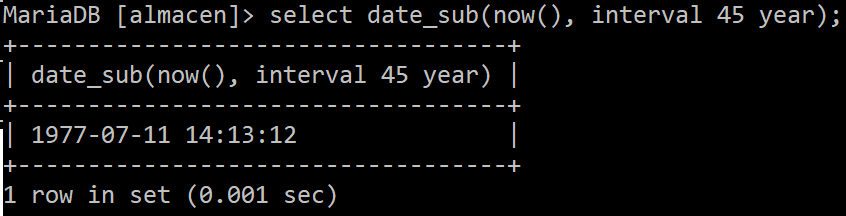
Los siguientes elementos pueden formar parte de expresiones en consultas:
● Operandos: Números o cadenas alfanuméricas.
● Operadores aritméticos: +, -, *, /, %.
● Operadores relacionales: <,>,<>,>=, <=, =.
● Operadores lógicos: AND, OR, NOT.
● Paréntesis: Estos operadores tienen prioridad lo que está dentro sobre lo de fuera.
● Funciones: date_add, concat, left, right, date_sub, etc.
Así que con estos operadores se pueden crear muchas más consultas y personalizarlas como ves a continuación:
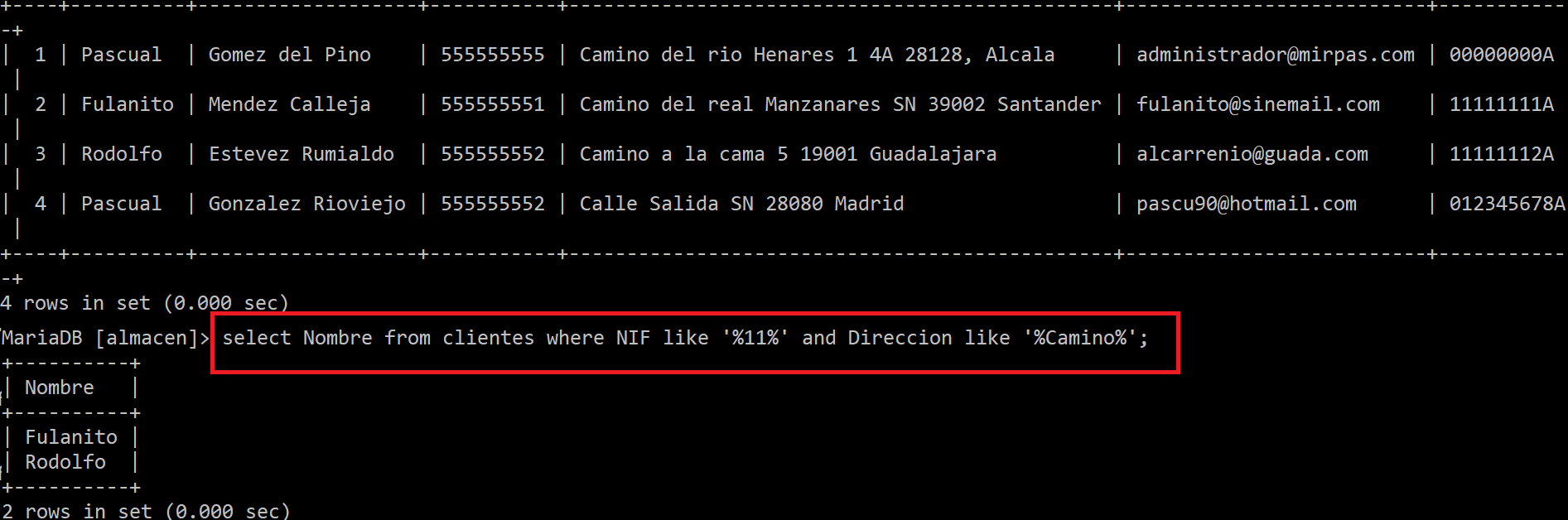
Fijate que uso otro condicional llamado LIKE que lo que me permite es buscar dentro de la cadena de la columna (su valor), algo parecido entre los simbolos %. Por eso como pongo que me muestre los resultado que de NIF tengan 11 al inicio de la búsqueda y además indico que la dirección empiece por 'Camino', me muestran dos registros, en lugar de los 4 de la tabla. Estos filtros se llaman filtros con test de patrón. En estos filtros se pueden sustituir un valor desconocido por el símbolo _. Esto hará en la consulta que si encuentra un carácter, por ejemplo "%_pera%" podrá buscar caracteres que empiecen por cualquier carácter o número siempre que el resto de cadena sea el que coincida. Esto se hace para buscar con like cadenas o partes de contenido que no se conoce o no se sabe si es mayúscula o minúscula.
Además se puede hacer un filtro con operador de pertenencia a conjunto mediante la clausula IN:
nombre_columna IN (value1, value2, ...)
Lo que permite comprobar si un valor dentro de una columna está contenido dentro del valor entre paréntesis y es muy parecido al LIKE.

Otro filtro para el operador de rango es BETWEEN que permite seleccionar los rangos que estén incluidos en un rango. Su sintaxis es:
nombre_columna BETWEEN value1 and value2
Esto se suele hacer para seleccionar los campos en que, por ejemplo un valor esté entre un porcentaje y otro.

Ordenación.
Seguimos con las consultas. La ordenación te permite ordenar los registros de la consulta de varias formas. La sintaxis es mediante el operador ORDER BY:
SELECT [DISTINCT] expresion_select [,expresion_select]... [FROM tabla]
[WHERE filtro][ORDER BY {nombre_columna | expr | posicion} [ASC | DESC], ...]
Los atributos más usados son ASC, para ordenación ascendiente, y DESC para ordenación descendiente. Por defecto coge el valor de ASC. Por ejemplo, para ordenar por nombre los clientes y por Id se realiza la siguiente consulta:

Orden by permite ordenar por campos tanto numéricos como alfanuméricos por lo que también puedes ordenar campos totalmente alfanumericos.
MySQL también permite ordenar por el número de elementos gracias al método count(*). Dicha consulta te devolverá un valor numerico en relación a la consulta. Es similar a la propiedad lenght de varios lenguajes de programación.
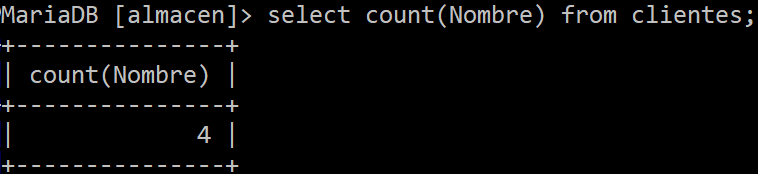
Además a estas consultas de ordenación se les puede agregar funciones (según el tipo de dato de la columna y que por lo general es numerica), como ves a continuación:
● SUM (expresión) #suma los valores pasados en el argumento.
● AVG (expresión) #Calcula la media de los valores.
● MIN (expresión) #Calcula el mínimo.
● MAX (expresión) #Calcula el máximo.
● COUNT(nombre_columna) #Cuenta el número de columnas.
● COUNT (*) #Igual que el anterior pero también cuenta los valores nulos.
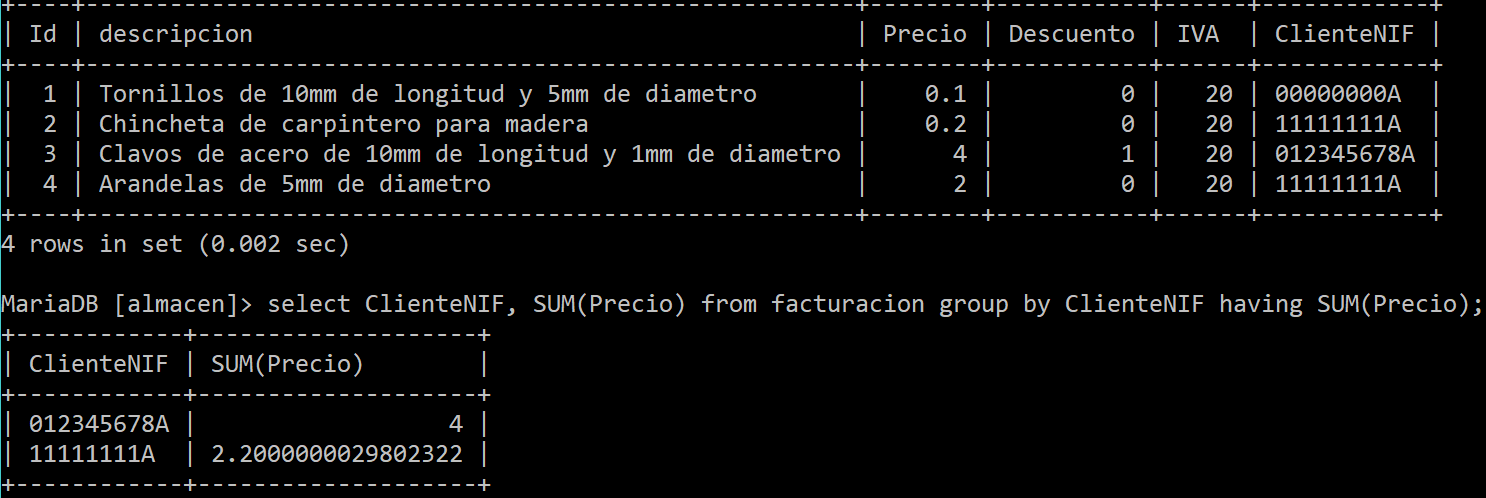
En la ordenación de elementos se pueden agrupar consultas. Esto se hace con el comodín GROUP BY. Por ejemplo en el siguiente script quiero saber cuantos Nombres hay repetidos en la tabla clientes.
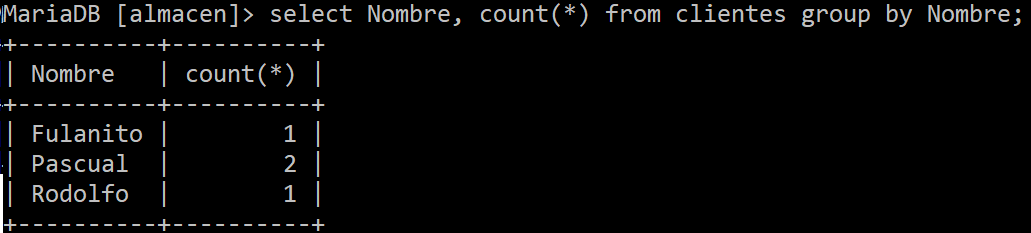
Rcuerda que Mysql no te permitirá mezclar funciones de una columna y columnas de una tabla sin escribir antes GROUP BY.
Para terminar, existe una consulta que agrupa varios filtros de grupos. Hasta ahora hemos usado la cláusula WHERE para indicar el destino de la ordenación o la consulta; ahora también usaremos HAVING según la sintaxis siguiente:
SELECT [DISTINCT] expresion_select [,expresion_select]... FROM tabla
[WHERE filtro][GROUP BY expr [,expr]...]
[HAVING filtro_grupos][ORDER BY {nombre_columna | expr | posición} [ASC|DESC],...]
HAVING aplica los mismos principios que la cláusula WHERE, pero su posición debe de ser después de esta cláusula ya que sino producirá un error. La diferencia entre una y otra cláusula viene dada por:
● La cláusula WHERE se aplica primero a las filas individuales de las tablas u objetos con valores de tabla correspondiente. Solo se agrupan las filas que cumplen las condiciones de la cláusula WHERE.
● La cláusula HAVING se aplica a continuación a las filas del conjunto de resultados. Solo aparecen en el resultado de la consulta los grupos que cumplen las condiciones HAVING. Solo puede aplicar una cláusula HAVING a las columnas que también aparecen en la cláusula GROUP BY o en una función de agregado.
Asi que, por así decirlo, la cláusula HAVING se puede utilizar para incluir condiciones con alguna función de tipo SUM, AVG, MAX, etc., etc.; mientras que la cláusula WHERE se dedica a especificar la consulta ya que no puede manejar funciones SQL.
Por ejemplo en la siguiente consulta quiero mostrar el precio que se ha gastado un cierto cliente en la tabla facturación de la clase anterior: